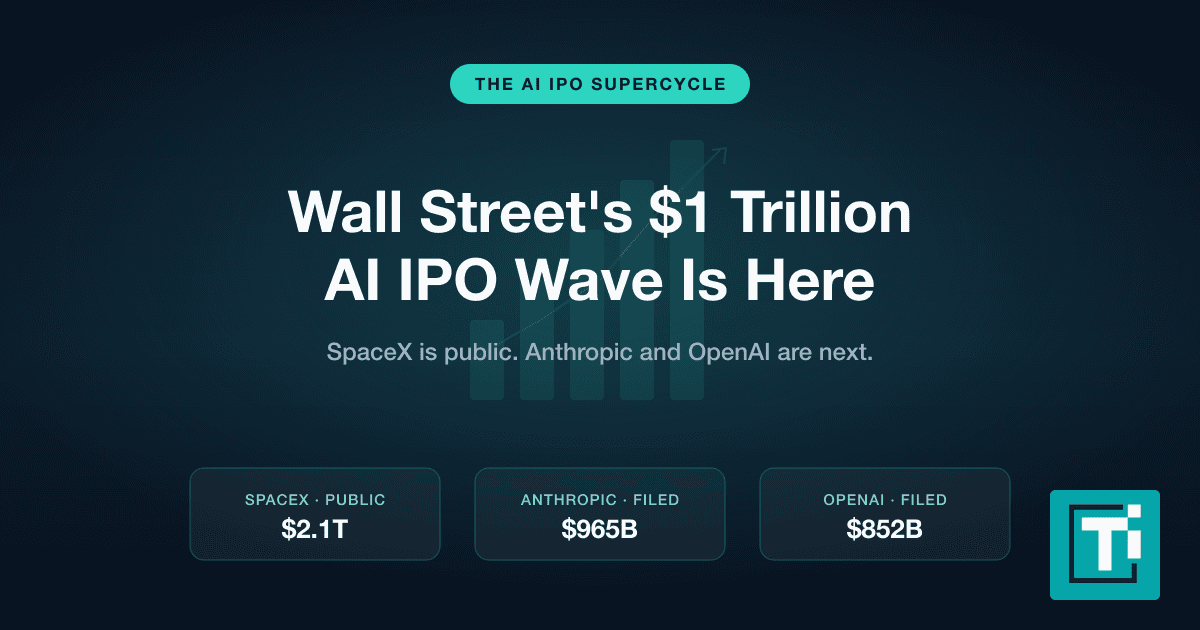
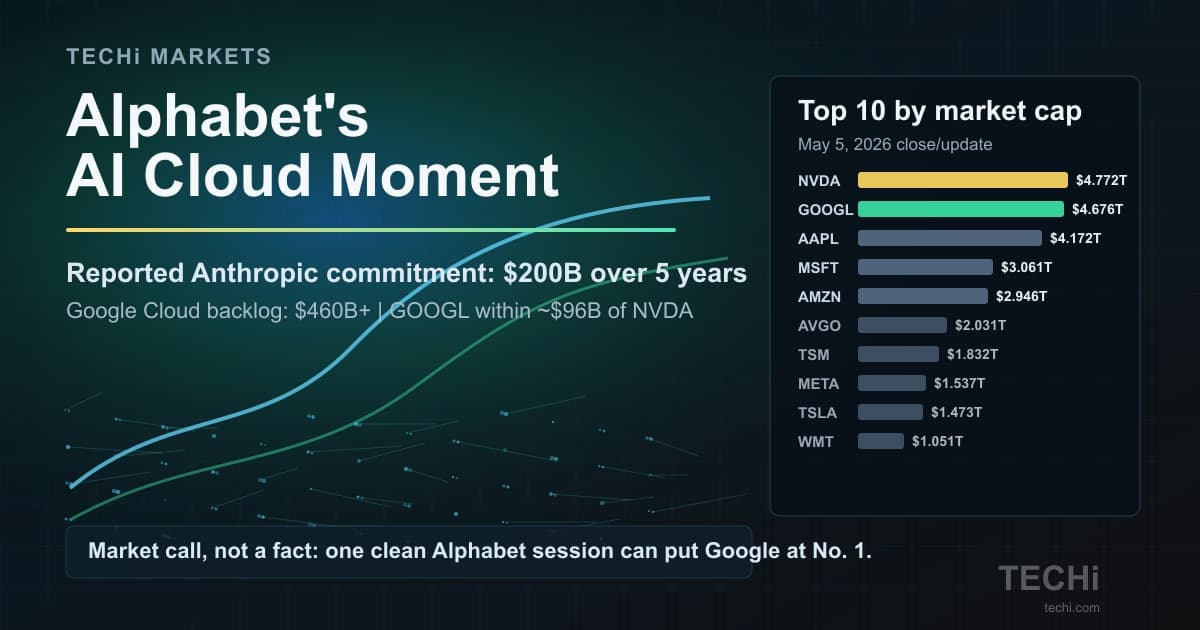
Dario Amodei, Anthropic's CEO, in a recent essay, explained how the company intends to accomplish AI systems understanding and transparency. The goal is to reliably find and fix problems within AI models by 2027. Amodei states,
"While tremendous progress has been made in AI, the overwhelming majority of researchers cannot explain how AI models arrive at their conclusions".
This interpretability gap presents grave risks as AI systems gain autonomy and become more integrated into the economy, technology, and even the national security infrastructure."
The Problem of AI's "Black Boxes:" A Disconcerting Trend
AI models powering virtual assistants, text generators, predictive systems, and even self-driving cars are predominantly "black boxes" with no transparent inner workings. This is particularly alarming in situations where mistakes happen, such as Openai's recently released o3 and o4-mini models, which claim to have mastered certain tasks only to hallucinate or fabricate multiple facts. Amodei considers the ambiguity surrounding AI development one of its hurdles. In the absence of a clear understanding of how certain models operate, the chances of harmful ideas or content generation become a possibility, alongside reckless outcomes within sensitive sectors such as healthcare or defence.
The Solution is AI "Brain Scans"
According to Amodei, transparency in AI requires a long-term proposal to perform "brain scan" or "MRI" analyses of AI systems. The founder of Anthropic outlines the goal for full-scope transparency as a centrepiece for long-term strategy. Trusting AI systems with sensitive information and issuing tasks requires a clear understanding of the system's information processing. AI responsible for processing large amounts of sensitive data will need to be inspected for biases, deception, and inappropriate spontaneous behaviour. Transparency on such a scale is estimated to be achieved within five to ten years, but it is deemed crucial for the further development of trusted and morally responsible AI. Anthropic has made strides toward mechanistic interpretability by locating 'circuits' within its models that show how particular decisions are made.
The Competition for Safety and Responsibility in AI
Unlike other tech giants, Anthropic's AI safety focus is markedly different. Other tech companies have been more conservative when it comes to imposing regulations. When the company faced California's controversial SB 1047 AI safety law, Anthropic was more than willing to support it and provided safe recommendations, reinforcing the AI ecosystem stance they have built throughout the years. With the advancement and growing prominence of AI systems, interpretability under Amodei's vision may well mark a paradigm shift in responsible AI development, trust, and understanding, as a prerequisite to unfettered autonomy. From this perspective, the understanding of AI systems will eventually need to match their development pace. The next frontier in AI is a multidimensional one, revolving around capabilities and a commitment to trustworthiness, where there are no smoke and mirrors, which Anthropic is determined to remove.
About the Author

Munazza Shaheen is an AI and technology researcher at TECHi with a deep interest in machine learning, automation, and emerging tech trends. Her work focuses on exploring the impact of artificial intelligence on industries, ethical AI development, and future innovations. She actively follows advancements in deep learning, robotics, and AI-driven solutions, contributing insights into how technology is shaping the world.