- The ChipsTPU 8t handles training, TPU 8i handles inference and AI agents. Google claims 2.8x better price-to-performance than the prior generation.
- OpenAI SignalOpenAI — historically Microsoft-Nvidia anchor customer — is now taking TPU capacity. The first visible crack in the single-vendor AI substrate.
- Anthropic + MetaAnthropic expanded to multiple gigawatts of next-gen TPU. Meta signed a multibillion-dollar multiyear deal in February 2026.
- Nvidia Exposure$193.7B of $215.9B FY26 revenue is data center, with hyperscalers at 50%+ of that mix. Hyperscaler diversification compresses unit growth before it compresses price.
- GOOGL vs NVDAGOOGL gains a high-margin revenue line if TPU bookings convert. NVDA keeps near-term dominance but loses the monopoly premium on long-dated cash flows.
Google just put a price on Nvidia's moat. At Google Cloud Next 2026 in Las Vegas on Wednesday, Alphabet unveiled TPU 8t and TPU 8i, two new custom AI accelerators claiming 2.7x better price-to-performance than their predecessors, and confirmed that Anthropic, Meta, and now OpenAI are buying multi-gigawatt allocations. The last name on that list is the tell.
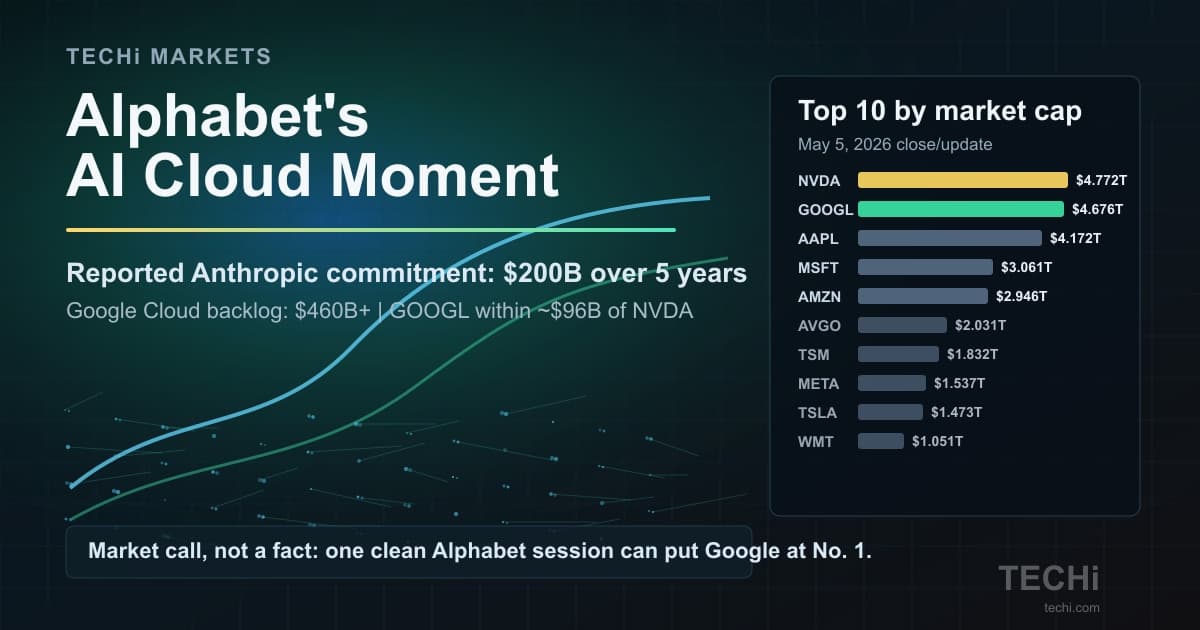
OpenAI has been the anchor customer of the Nvidia franchise for the entire ChatGPT era. A confirmed OpenAI booking on Google silicon is the first visible crack in the assumption that Nvidia GPUs are the only serious substrate for frontier AI. GOOGL closed Tuesday at $332.29. NVDA closed at $199.88. The spread between those two charts is about to matter more than it did last week.
Prices at Tuesday, April 21, 2026 close. Markets reopen at 9:30 AM ET.
What Google Actually Announced
The two chips are purpose-built for the two halves of the AI workload that Nvidia currently dominates end to end. TPU 8t is a training-class accelerator, the silicon that large labs use to pre-train frontier models. TPU 8i is tuned for inference and AI agents, the workload that runs every time a ChatGPT-style assistant answers a query or an autonomous agent takes an action. Google is claiming 2.7x better price-per-training-hour against its own prior generation and a development-cycle compression that takes frontier model work "from months to weeks."
Under the hood, the roadmap leans on partners. Bloomberg reported earlier this week that Broadcom co-designed TPU 8t for training (codenamed "Sunfish"), while MediaTek handles TPU 8i for inference (codenamed "Zebrafish"). TSMC handles fabrication. Marvell Technology is separately in talks to co-design a future memory processing unit and an additional inference TPU, though that deal has not been finalized. Alphabet is not trying to vertically integrate every layer of the stack; it is assembling a hyperscaler supply chain that runs parallel to Nvidia's. That matters for gross margin, for capacity ramp, and for the strategic dependency math every hyperscaler CFO is now running.
Alphabet's own Google Cloud blog framed the launch as the first release in a yearly TPU cadence designed to match, not lag, Nvidia's annual Blackwell-to-Rubin-to-Vera-Rubin roadmap. That cadence claim, if it holds, is a bigger problem for Nvidia than the benchmark numbers.
The OpenAI Signal Changes the Story
The customer roster attached to the announcement is why this is a market event, not a keynote event:
- Anthropic: expanded to "multiple gigawatts" of next-generation TPU capacity for Claude training and serving. Anthropic is now the largest publicly disclosed TPU customer.
- Meta: the multibillion-dollar multiyear deal signed in February 2026. Meta spends the most on AI capex of any Western company. Choosing TPU for any non-trivial slice of that budget is a statement.
- OpenAI: now taking TPU capacity. This is the headline shift. OpenAI trains on Microsoft-procured Nvidia clusters. A confirmed Google chip allocation tells every other buyer that the switching cost is not infinite.
None of this means Nvidia loses. It does mean the "single-vendor AI substrate" narrative that justifies Nvidia's valuation premium has its first serious counter-example with real dollars attached.
The Investable Shift
Two years ago, custom silicon was a hyperscaler science project. Today it is a procurement strategy. Every frontier lab with a multibillion-dollar training budget now has a credible reason to dual-source. Google is the primary beneficiary because it is the only hyperscaler that built its TPU program before the AI boom and can sell capacity rather than consume all of it internally.
Nvidia Exposure in Plain Numbers
The math on the other side of this announcement is not theoretical. Nvidia's fiscal 2026 data center revenue was $193.7 billion of $215.9 billion total, roughly 90 percent of the top line. Inside that data center line, hyperscalers are estimated at more than half of the buyer mix. When those same hyperscalers start routing workloads to internal or partner silicon, the pressure shows up as unit growth deceleration first and pricing pressure second.
The cleanest comparison is not GOOGL versus NVDA — it is Alphabet's ability to monetize TPU capacity at hyperscaler gross margins versus Nvidia's ability to continue selling into the same TAM at 70-plus percent gross margins. The first scenario takes revenue share. The second takes margin points. Both show up on the same income statement.
Marvell (MRVL) is the obvious second-order beneficiary. TECHi covered the setup in the recent Marvell rally analysis. The stock was up 84 percent into this announcement specifically because the market already priced in Marvell's role as Google's custom-silicon partner.
What This Means for GOOGL and NVDA
For Alphabet (GOOGL), the TPU franchise is transitioning from a cost center that reduces Google Cloud's Nvidia bill into a revenue line that sells compute to competitors. That is a structurally better business model. If TPU capacity booked by Anthropic, Meta, and OpenAI scales as signaled, Google Cloud's AI infrastructure segment becomes one of the fastest-growing lines in the S&P 500.
For Nvidia (NVDA), the near-term revenue picture is unchanged. Blackwell Ultra is sold out. Rubin demand is locked for 2026. What changes is the narrative slope on FY2028 and beyond. Nvidia is no longer the only answer, and the market has to price that.
The Risk on the Bull Case
TPU price-performance claims are vendor-reported. Real-world benchmarks from Anthropic or Meta workloads have not been independently audited. CUDA's software moat is a decade deep. Every frontier lab has PyTorch, Triton, and inference stack tooling built around Nvidia. Porting workloads to TPU is a software engineering tax that vendor benchmarks do not capture. If Google cannot close the software gap, the hardware wins do not translate into sticky revenue.
Readers sizing positions across the AI capex cycle should pair this with the broader AI stocks shortlist, which covers the second- and third-order beneficiaries: memory suppliers, networking, power, and the inference specialists that gain relevance as hyperscaler capex diversifies.
The next real catalyst is Alphabet's Q1 2026 earnings call. The question every analyst will ask, in some form: how much of the TPU pipeline is now contracted revenue versus capacity commitments. The answer frames GOOGL's re-rating case. It also frames how much Nvidia's multiple has to compress.
FAQ
Frequently asked questions
What are Google TPU 8t and TPU 8i?
TPU 8t is Google's new training-optimized AI accelerator. TPU 8i is tuned for inference and AI agents. Both were announced at Google Cloud Next 2026 on April 22, 2026, with Google claiming 2.7x better price-to-performance against the prior TPU generation.
Who are the main customers for Google's new TPU chips?
Anthropic has expanded to multiple gigawatts of next-generation TPU capacity. Meta signed a multibillion-dollar multiyear deal in February 2026. OpenAI is now taking TPU capacity, which is the most significant commercial signal because OpenAI historically trained on Nvidia GPUs.
Does this end Nvidia's dominance in AI chips?
No. Nvidia's fiscal 2026 data center revenue was $193.7 billion, Blackwell Ultra is sold out, and Rubin demand is locked for 2026. What changes is the long-term narrative: Nvidia is no longer the only credible substrate for frontier AI, which puts pressure on the valuation premium assigned to a single-vendor moat.
Which other companies benefit from Google's TPU expansion?
Broadcom co-designed TPU 8t for training and MediaTek handles TPU 8i for inference. TSMC handles fabrication. Marvell Technology is in talks to co-design a future memory processing unit and an additional inference TPU. Marvell was a key beneficiary heading into the announcement on its potential expanding role.
Should investors buy GOOGL or NVDA after this announcement?
Both stocks remain core AI positions with different risk profiles. GOOGL gains a new high-margin revenue stream if TPU bookings convert. NVDA keeps near-term dominance but faces long-term narrative compression. The decision depends on time horizon and existing portfolio exposure, not on a single-day event.
Disclaimer
This article is for informational purposes only and does not constitute financial, investment, tax, or legal advice. Market data, tax rules, and prices can change after the article date. TECHi and its authors may hold positions in securities or digital assets mentioned. Always conduct your own research and consult a licensed financial, tax, or legal professional before making decisions.
About the Author

Omer Sheikh covers Elon Musk-led and Musk-adjacent companies for TECHi, with a focus on Tesla, xAI, SpaceX, X, Neuralink, The Boring Company, and the public-market read-throughs from their product cycles, capital needs, AI infrastructure plans, supply chains, and regulatory risk. He also follows MicroStrategy/Strategy and its Bitcoin treasury strategy, using his finance background to connect balance-sheet decisions, capital markets, valuation, catalysts, and downside risk. His work is built for readers who want the investment case behind the headline: what changed, what it means for cash flow or market value, and what would prove the thesis wrong.